手書き数字をコンピュータに読ませて入力作業を自動化するため、画像から特定の領域にある数字を切り出すプログラムを書きました。
なお、本記事の内容は「数字認識を使って棚卸を自動化するアプリケーションを作る」で行った処理のひとつとなっています。
切り出す方法
まず事前に画像の傾きを補正してほぼ水平な状態にしておきます。
www.yakupro.info
画像全体を探すのではなく、数字が書かれているのは下図のように特定の領域なので、その領域の行と列をループカウンタとしたfor文を回すことで1行1列ずつ数字画像を切り取っていきます。
画像中にマーカーとなる「■」をいくつか置いておき、この位置を足がかりにしながら定期的に基点を更新することにより、切り出し位置のズレが大きくならないようにします。
ポイントは以下の2点です。
- 基点となる複数のマーカーの位置を取得する
- 切り出し位置の座標がずれていかないようにマーカーの検出位置で補正する
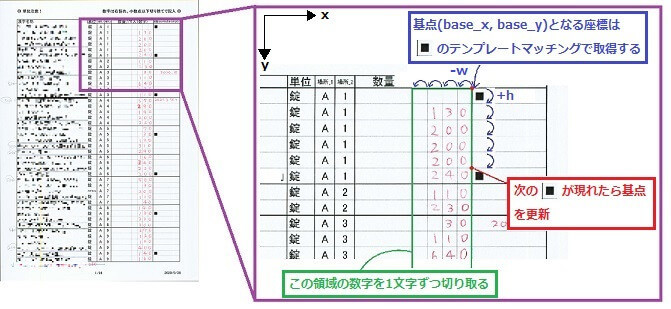
複数のマーカーの位置をテンプレートマッチングで取得する
前回記事「Pythonで画像の傾きを補正して水平にする」では画像中に検出対象が一つしかなかったのでcv2.minMaxLoc() 関数を使ってもっとも類似度が高いものを取得しました。しかし今回のケースでは画像中に検出対象が複数あり、それぞれについて一つの位置を得なければならないので、少し工夫が必要になります。
cv2.matchTemplateの戻り値の中身
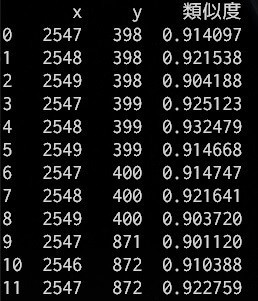
以下コードのcv2.matchTemplate()で得られたresultには、対象画像におけるテンプレート画像の各位置での類似度が入っています。以下のコードで確認してみます。
import numpy as np import pandas as pd import cv2 img = cv2.imread('test.jpg', 0) template = cv2.imread('template.jpg', 0) result = cv2.matchTemplate(img, template, cv2.TM_CCOEFF_NORMED) threshold = 0.9 # 類似度の設定(0~1) loc = np.array(np.where(result >= threshold)).T # threshold以上の位置(y, x) sim = result[loc[:, 0], loc[:, 1]].reshape(len(loc), 1) # 位置(y, x)の類似度 # loc, simを列方向に結合して[x, y, 類似度]となるよう列を入れ替え pos_ary = np.concatenate([loc, sim], axis=1)[:, [1, 0, 2]] # pandasデータフレームとして表示 df = pd.DataFrame(pos_ary, columns=['x', 'y', '類似度']).astype({'x': np.uint16, 'y': np.uint16}) pd.set_option('display.unicode.east_asian_width', True) print(df)
<実行結果>
thresholdで設定した類似度以上であった位置(座標)とその類似度が表示されます。
複数の検出結果の中から位置を一つだけ選ぶ
実行結果の(x, y)を見ると、行番号0~8までは画像中の同じ箇所についての結果であろうということがわかります。

これらを1つのグループ(互いの距離が10以内のもの同士など)とみなして、グループ内でもっとも類似度が高い座標をマッチング結果として採用したいところですが、実際やってみたところ、コードが複雑になる割に結果(切り出し画像の正確さ)が劇的に良くなるというようなことはありませんでした。
そのため、ここは簡潔さを優先してlocを順番に見ていき、前の座標との距離が10以上離れていれば採用、という単純な方法で実装することにしました。
threshold = 0.9 loc = np.where(result >= threshold) prev_pos = (0, 0) pos_ary = [] # 結果位置を格納 # 1つの箇所につき複数の(x, y)が得られるため、各箇所における最初の座標を採用する for top_left in zip(*loc[::-1]): # top_left: (x, y) # 前回位置との距離 dist = np.linalg.norm(np.array(top_left) - np.array(prev_pos)) if dist >= 10: pos_ary.append(top_left) prev_pos = top_left print(pos_ary) # [(2547, 398), (2547, 871), (2546, 1528), (2544, 2184), (2544, 2841), (2544, 3499), (2543, 4161)]
数字の切り出し処理
行、列をループカウンタとして、切り出す数字画像の左上の座標を更新していきます。
# 画像から数字の切り出しを行う def clip_num(img, markerpos, max_row=42, col=4, h=94, w=88): """ img: 画像 markerpos: 検出したマーカーの位置座標(x, y)の配列 max_row: 最大行数. 画像ファイルごとに与えても良い col: 最大列数 h: 切り出す数字画像の縦の長さ(1行の高さ) w: 切り出す数字画像の横の長さ(1列の幅) """ num_files = {} # {ファイル名: 切り取った数字のimg} idx = 0 # マーカー配列がない(全く検出されなかった)場合は決め打ち if len(markerpos) == 0: base_x, base_y = (2542, 395) else: base_x, base_y = markerpos[idx] for r in range(1, max_row+1): for c in range(1, col+1): # 右端が1列目 # 対象領域の切り出し num_img = img[base_y:base_y + h, base_x - w:base_x] # 保存ファイル名は'num行_列.png' f_name = format_fname(r, c) num_files[f_name] = num_img # 次のマスの基点はw分左に移動する base_x -= w base_x += w * col # x座標をcol列分右に戻す base_y += h # y座標を1行分下に移動する # idxが末尾でない, かつ(現在のy座標+α)が次のマーカーを超えていれば基点を更新 if idx < len(markerpos) - 1 and base_y + h/2 > markerpos[idx+1][1]: base_x, base_y = markerpos[idx+1] idx += 1 return num_files

まず最初の行の基点(base_x, base_y)は上のテンプレートマッチングで得た位置配列の最初の要素で初期化します。あとは一列左に動けば-w(1列の幅)、一行進めば+h(1行の高さ)して基点を更新しているだけです。
そのままだとループ(行)が進むにつれてわずかなズレが蓄積していくため、現在のy座標+αが次のマーカー■のy座標を超えていれば、基点を更新しています。
切り取った画像は保存ファイル名をキー、画像を値とした辞書に保存し、1ページ(1画像)分終了するとその辞書を返します。なお、数字画像がどこの位置のものかが数字認識時にわかるようにするために、ファイル名は行と列から作成するようにしました。
また、切り出し画像の幅と高さが中途半端な数字ですが、これはスキャン画像に合わせただけで特に深い意味はありません。
<実行結果>
マーカーの位置を足がかりとしたことで、最下行までズレることなくうまく切り取れています。
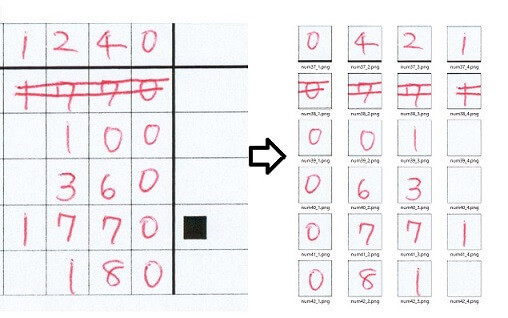
OpenCVのマスク処理で背景の枠線を消す
切り出しはうまくいきましたが、一つ一つの画像をみるとExcelで作成した枠線が残ってしまっています。この枠線は数字をできるだけはみ出さずに書いてもらうために必要なものですが、これが残ったままだと数字認識の際に誤認識の原因となるので、切り出しする前にOpenCVのマスク処理で取り除いておきます。
マスク処理とは
対象画像に抽出したい領域のみを示すマスク画像を用いてマスク処理を行うと特定の領域だけを抽出することができます。

マスク画像は対象画像と同じ大きさで抽出したい部分のみ白、それ以外は黒の2値画像です。
HSV色空間を利用して抽出したい領域を指定する
今回抽出したいのは赤色のボールペンで書かれた手書きの数字部分です(この処理のために黒ではなく赤色で手書きすることにしました)。この部分だけを抽出領域として指定するために、読み込んだ画像データを以下のコードでBGR(青、緑、赤)*1からHSV色空間に変換してHSVの配列を得ます。
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV) h = hsv[:, :, 0] # h: 色相 0~179 s = hsv[:, :, 1] # s: 彩度 0~255 v = hsv[:, :, 2] # v: 明度 0~255 print(hsv.shape) # (4676, 3306, 3) print(h.shape) # (4676, 3306)
HSV色空間では色相(Hue)、彩度(Saturation)、明度(Value)の3つの数値の組み合わせで色を表現します。読み込んだBGR画像と変換後のh、s、vをcv2.imshow()で表示させてみたものがこちらです。
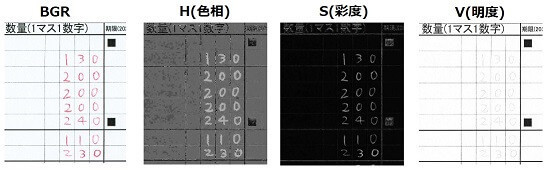
数字部分と枠線に注目して見てみると、Sは両者の違いがあまりはっきりしませんが、HとVは一方が割りと奇麗に見えます。条件をうまく設定してやれば、数字だけを抽出することができそうです。
HSVについてもう少し見てみます。
H(色相)の取る範囲は一般的には0~360ですが、OpenCVでは0~179となっており、値がどの色に相当するかを図にしたものがこちらになります。

色相は本来は環状であるため赤は両端にありますが、これでみると赤はだいたい150~10くらいのようです。彩度と明度については、大きい方が鮮やかで明るくなり、小さいと薄く黒くなります。
次に、条件の調整方法についてです。この色空間では色はH(色相)の値でほぼ決まるそうなので、だいたい見当をつけて最初に適当な数値を設定してから、結果を見て調整していっても良いのですが、今回はシビアに抽出したいと思ったので、画像のHSVを調べることのできるこちらのサイトを利用しました。
『ここに画像をドラッグして下さい』のところに色情報を調べたい画像を持っていきます。

その後、抽出したい部分をクリックするとその部分の色情報を確認することができます。ひと口に赤色といっても薄い・濃い、明るい・暗いとあるので、だいたいこの辺かな、というところを何点かクリックしてみました。
ただ、このページで見られるHSVの範囲はHが0~360、S, Vは0~100なので、OpenCVの範囲に合うようHなら×0.5、S、Vなら×255/100して変換してやります。
後は作成したマスク画像をその都度確認しながら微調整しました。
色相の帯の図では赤は0~10くらいも入っていましたが、今回のケースではどうやらHは155以上179以下の狭い範囲にしぼることができそうです。
これで抽出したいHSVの範囲がわかったので、その情報をもとにマスク画像を作成します。
mask = np.zeros(h.shape, dtype=np.uint8) # 8ビットの符号なし整数(0~255) mask[(h >= 155) & (s >= 10) & (v >= 229)] = 255
h, s, vの各値が条件に当てはまる位置に255を代入しています。sは緩く(広く)、hとvは厳しく(狭く)設定しました。厳しすぎると、邪魔な枠線を消せても目的の数字自体もかすれてしまったりするので難しいところです。
このコードのmaskへの代入の式はcv2.inRange()を使って以下のように書くこともできます。
# HSVで赤色の範囲を定義する lower_red = np.array([155, 10, 229]) upper_red = np.array([179, 255, 255]) # 指定した範囲を255で塗りつぶす mask = cv2.inRange(hsv, lower_red, upper_red)
cv2.inRange()は指定した範囲を255、それ以外は0で埋めて返します。
cv2.bitwise_and()でAND演算を行う
AND演算とは2つの入力値が両方とも1(真)のときだけ、演算結果として1(真)を返す論理演算です。表にすると次のようになります。
| A | B | A AND B |
|---|---|---|
| 1 | 1 | 1 |
| 1 | 0 | 0 |
| 0 | 1 | 0 |
| 0 | 0 | 0 |
たとえば、あるピクセルの色がRGB=(255, 25, 35)だとすると、これは2進数表記では(11111111, 00011001, 00100011)となります。これに対して、もう一方の入力が(255, 255, 255)だったとき、各々のRGBでAND演算を行うと元のピクセルと同じ色(255, 25, 35)が得られます。しかし、もう一方の入力が(0, 0, 0)の場合の出力は(0, 0, 0)となります。
OpenCVのcv2.bitwise_and()はビット単位でのAND演算を行います。
ドキュメントによると、maskが8ビットのシングルチャンネル配列でsrc1とsrc2が同じサイズの配列のときは
とあります。マスク画像mask[i]が0でないところはsrc1[i]とsrc2[i]のAND演算を行ったものが出力画像dstとして得られるということです。(ちなみに、上の方でmaskには255を代入しましたが、0でないところでANDを行うのであれば、255でなくても良いのかな..。試してみたところ、 0以外であれば結果の出力画像としては同じものが得られました。)
src1とsrc2に引数として同じ画像を渡せば、結果的には、マスク画像の0でないところだけが抽出された(それ以外の部分は0(=黒)の)画像が得られます。
コードで書くと以下のようになります。
dst_img = cv2.bitwise_and(img, img, mask=mask)
出力dst_imgを表示すると、上図の一番右側<マスク処理後>の画像が得られました。
最終的には背景を白にしたかったので、下のコードで黒(0, 0, 0)のところだけ255を代入して白に反転させます。
dst_img[dst_img == [0, 0, 0]] = 255
<実行結果>
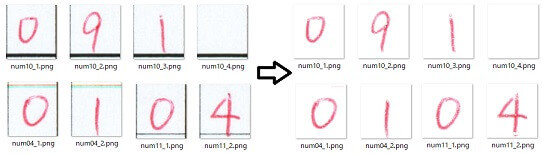
赤の手書き数字の部分だけを残して黒い枠線を消すことができています。
cv2.bitwise_and()を2つの引数で行うには
2枚の画像で一方をマスクとして適用するには、マスクとして用いる画像の配列の形状を対象画像と同じにしてやります。
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV) h = hsv[:, :, 0] # h: 色相 0~179 s = hsv[:, :, 1] # s: 彩度 0~255 v = hsv[:, :, 2] # v: 明度 0~255 mask = np.zeros(hsv.shape, dtype=np.uint8) # imgと同じ形状(4676, 3306, 3) mask[(h >= 155) & (s >= 10) & (v >= 229), :] = 255 dst_img = cv2.bitwise_and(img, mask)
元のカラー画像が3チャンネルなので、np.zeros()で作成するときも(縦、横、チャンネル)の3次元配列で作成して、抽出したい位置のチャンネルすべてに255を代入してマスク画像とします。対象画像とこのマスク画像をsrc1、src2としてcv2.bitwise_and()に与えると先ほどのコードと同じ結果が得られます。
参考
・色空間の変換 — OpenCV-Python Tutorials
・pythonで赤い物体を認識しよう #Python - Qiita
")
記事はこちらに続きます。
www.yakupro.info
import glob, math, os import numpy as np import cv2 # 水平にした画像ファイルから数字部分のみを切り出す # 数字位置座標を決めるための黒塗り正方形マーカの位置を検出し、その位置を返す def detect_makers_position(img, marker, threshold=0.9): # 回転作業の後は劣化を避けるため上書きせずにimgのままで受け取る gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) template = cv2.imread(marker, 0) # マッチング result = cv2.matchTemplate(gray_img, template, cv2.TM_CCOEFF_NORMED) loc = np.where(result >= threshold) prev_pos = (0, 0) pos_array = [] # マーカ-の位置を格納 # 1つの箇所につき複数の(x, y)が検出されるため、最初に検出した座標を採用する for top_left in zip(*loc[::-1]): # top_leftは(x, y)として得られる # 前回検出した位置よりも距離が10以上離れているものだけ加える dist = np.linalg.norm(np.array(top_left) - np.array(prev_pos)) if dist >= 10: pos_array.append(top_left) prev_pos = top_left return pos_array # 与えられた行, 列からファイル名を作成して返す def format_fname(r, c): return 'num' + str(r).rjust(2, '0') + '_' + str(c) + '.png' # 画像から数字の切り出しを行う def clip_num(img, markerpos, max_row=42, col=4, h=94, w=88): """ img: 画像 markerpos: 検出したマーカーの位置座標(x, y)の配列 max_row: 行数. 画像ファイルごとに与えても良い col: 最大列数 h: 切り出す数字画像の縦の長さ(1行の高さ) w: 切り出す数字画像の横の長さ(1列の幅) """ num_files = {} # {ファイル名: 切り取った数字のimg} idx = 0 # マーカー配列がない(全く検出されなかった)場合は決め打ち if len(markerpos) == 0: base_x, base_y = (2542, 395) else: base_x, base_y = markerpos[idx] for r in range(1, max_row+1): for c in range(1, col+1): # 右端が1列目 # 対象領域の切り出し num_img = img[base_y:base_y + h, base_x - w:base_x] # 保存ファイル名は'num行_列.png' f_name = format_fname(r, c) num_files[f_name] = num_img # 次のマスの基点はw分左に移動する base_x -= w base_x += w * col # x座標をcol列分右に戻す base_y += h # y座標を1行分下に移動する # idxが末尾でない, かつ(現在のy座標+α)が次のマーカーを超えていれば基点を更新 if idx < len(markerpos) - 1 and base_y + h/2 > markerpos[idx+1][1]: base_x, base_y = markerpos[idx+1] idx += 1 return num_files # 枠線を消す.文字が赤のボールペンで書かれているのが前提. def delete_grid(img): hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV) h = hsv[:, :, 0] # h: 色相 0~179 s = hsv[:, :, 1] # s: 彩度 0 ~255 v = hsv[:, :, 2] # v: 明度 0~255 mask = np.zeros(hsv.shape, dtype=np.uint8) # 8ビットの符号なし整数(0~255)のゼロで初期化された配列 mask[(h >= 155) & (s >= 10) & (v >= 229), :] = 255 dst_img = cv2.bitwise_and(img, mask) dst_img[dst_img == [0, 0, 0]] = 255 # 黒の部分のみ白に反転させる return dst_img # 与えられたフォルダの全てのファイル(フルパス)をソートしてリストで返す def get_sorted_files(dir_path): return sorted(glob.glob(dir_path)) # 受け取ったフォルダ名(dir_name)の下にjpgファイル名のフォルダを作成してそのパスを返す. def make_output_dir(dir_name, jpg_path): current_dir = os.path.abspath( os.path.join(os.path.dirname(jpg_path), os.pardir)) f_name, ext = os.path.basename(jpg_path).split('.') target_dir_list = [current_dir, dir_name, f_name] # f_nameは"A1", "B2"などの場所情報 target_dir = os.path.join(*target_dir_list) os.makedirs(target_dir, exist_ok=True) return target_dir if __name__ == '__main__': current_dir = os.path.dirname(os.path.abspath(__file__)) jpg_dir = '/jpeg/*' # スキャンした画像データを入れておく # jgpファイルをソートしてリストに取得 jpg_files = get_sorted_files(current_dir + jpg_dir) for jpg_file in jpg_files: print(jpg_file) # ----- 回転処理 ----- # 関数本体は前回記事<Pythonで画像の傾きを補正して水平にする>参照 left_pos = detect_marker(jpg_file, "./template/left_marker.jpg") right_pos = detect_marker(jpg_file, "./template/right_marker.jpg") angle = calc_rotation_angle(left_pos, right_pos) rotated_img = rotate_img(cv2.imread(jpg_file), angle) # cv2.imwrite(jpg_file, rotated_img) # JPEGは上書き繰り返すと劣化するのでしない # ----- 画像中の数字の切り出し処理 ----- pos_array = detect_makers_position(rotated_img, './template/square.jpg') img = delete_grid(rotated_img) # 枠線の消去 # 切り出した数字ファイルを保存するためpngフォルダを作成する. # jpg_file名のA1, B2などをフォルダ名とする output_path = make_output_dir('clipped_png', jpg_file) png_files = clip_num(img, pos_array) # png_files{key: ファイル名, value: pngファイル} for f_name, png in png_files.items(): png_file = os.path.join(output_path, f_name) cv2.imwrite(png_file, png)
*1:OpenCVのimread()でカラー画像を読み込むと色の順番はRGBではなくBGRになります。