機械学習ライブラリにおける画像分類のチュートリアルなどで目にすることが多い手書き数字認識ですが、実際の業務で行う棚卸で利用することができそうだと考え、あれこれ試行錯誤してやってみました。とりあえず実用で使えるレベルで形になったので、書いていきたいと思います。
手書き数字認識とは
手書きの数字画像が0~9のどの数字であるかを正しく分類しようというタスクです。
下図はMNISTという数字画像と正解ラベルがセットになっているデータセットの数字画像の例です。このデータセットの訓練用画像で学習を行い、学習したモデルでテスト用画像をどれだけ正しく分類できるかを計測する、といった使い方をします。
<MNIST画像データセットの例>

手書きの数字(文字)というのは人によって個性(くせ)があったり、国や地域によっても書き方が異なる場合があるようです。たとえば「7」だと1画で書かれたものもあれば、長い縦棒部分に短い横棒が入っているものがあったりします。
このような違いがあっても、人が「7」だと認識するのは難しいことではありませんが、プログラムがこれらの違いを吸収して「7」を正しく認識できるかというところに難しさがあります。
作成するアプリケーションの概要
私の職場での棚卸作業の流れはだいたい次のようになっています。
- 採用薬マスタからExcelVBAで棚卸記入用紙を作成、印刷する
- 実際に在庫を数えて用紙に記入する
- 用紙に書かれた在庫数をPCに手作業で入力する
- ExcelVBAで集計・在庫金額を出して提出用のフォーマットに整形する
自動化する部分
上の作業の内、今回自動化するのは3番目の「用紙に書かれた在庫数をPCに手作業で入力する」部分です。
もう少し具体的に言うと、コピー機でスキャンして画像データにした後、書いてある数字部分をコンピュータ(学習した画像識別モデル)に読ませることで人間が行っていた入力作業を自動化する、ということです。
入力作業自体は数十枚程度のことですが、この自動化によって、手間と時間を節約しようというのが今回作成するアプリケーションの目的です。
このような自動化を行うための工程は、だいたい以下のように分けられます。
<スキャンした画像データ>

↓
<手書き数字の切り出し(1文字ずつに分解)>

↓
<大きさ・位置の補正やノイズ除去等の前処理>
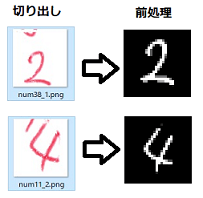
↓
<数字認識>
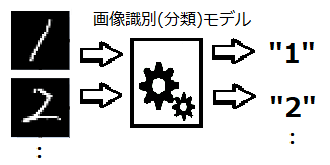
↓
<読み取った数字の入力>
ひと言でいうと、OCR(光学文字認識:画像データのテキスト部分を認識して文字データに変換する機能)をやってみたい、ということになるでしょうか。
しかし、今回作成するアプリケーションはGoogleドライブなどで使える写真のOCRとは以下の点で異なります。
数字が書かれている場所は決まっており、対象領域が限定されているので画像データのどこに数字があるかを探す必要はありません。また、書かれている文字も郵便番号のように0~9の数字だけとわかっているので、写真のOCRに比べると難易度的にはそれほど難しくはない・・・はずですが、それなりに苦労した点もありました。
精度を決めるポイント
アプリケーションを作成する上で要所となるのは次の2点です。
- 手書き数字の切り出しと前処理*1
- 数字認識(学習したモデルによる数字の分類)
MNISTデータセットにおいては、シンプルなCNN(畳み込みニューラルネットワーク)を使っても現在は99%以上の精度で分類できるので、「数字認識」の部分にはアプリケーションの精度向上の潜在的な伸びしろはほぼありません。
要するに、アプリケーション全体の精度を決めるのは「手書き数字の切り出し」と「前処理」部分の工程であり、ここに注力すべきということになります。理屈の上では、これらの部分がうまく機能すれば、コンピュータに99%に近い精度で手書き数字を入力させることができるはず、というわけです。
OpenCVによる画像データの前処理
OpenCVとはオープンソースの画像・映像を処理するライブラリで、もともとはC/C++で開発されたものだそうですが、JavaやPythonなどの言語でも使うことが可能です。
ライブラリでは画像のサイズ変更や回転、ノイズの除去や輪郭の抽出、グレースケール変換など様々な高度な機能が提供されており、数字の切り出しと前処理の工程では主に以下のような処理でOpenCVを使用しました。
- スキャナーで読み込んだ画像を回転して水平にする
- 切り出し枠の正確な座標を得る
- 枠線を消して数字だけを浮かび上がらせる
- 数字の大きさや位置を補正してノイズを除去する
これらの処理について書いた記事のリンクを貼っておきます。
こちらの記事では実行環境やスキャナー設定の情報も書いています。
www.yakupro.info
こちらはマスク処理による背景の消去と数字の切り出しです。
www.yakupro.info
切り出した数字画像の前処理について
www.yakupro.info
手書き数字データの収集と使用したモデル
手書き数字の分類はSVM(サポートベクターマシン)や多層ニューラルネットワーク等でも行うことができますが、実用に耐える精度を目指したので画像に対して認識率の高い結果を出す深層学習(ディープラーニング)を行うCNN(畳み込みニューラルネットワーク)を使用しました。
学習のための画像データは前述したようにMNISTデータセットを使用しましたが、このデータセットで学習した後、自前でデータを収集してそちらを使った学習も行いました。
この辺の試行錯誤について、自分の勉強した復習を兼ねて少しずつ書いていきました。
こちらの記事はCNNモデルを作成して学習を行い、読み取った数字をファイルに入力する方法について書いています。
www.yakupro.info
集めた手書き数字画像をプログラム中で簡単に使えるようデータセットを作成しました。
www.yakupro.info
作成したデータセットを使って、CNNを再学習し精度を向上させました。
www.yakupro.info
まとめ
最終的には、アプリケーション中で画像分類モデル(CNN)が読む手書き数字の精度は99.7%という高い精度にまでなりました。すべて完成してから棚卸は1回しかしていませんが間違えて入力された数字は1つだけ、という結果でした。(この結果にはモデルの精度の高さ以外にも理由があります。作業をする人は自分が書いた数字をコンピュータが読むことをわかっていたからでしょう。要するに、アプリケーション側に人間の方が歩み寄ったためです。)
もちろん、誤認識の可能性はゼロではありませんので、アプリケーションが入力した後には人間の目で確認するという作業は必要ですが、手作業でやっていたときと比べて大きく時間と手間を節約することができるようになりました。
参考
・機械学習|Coursera -Application example: Photo OCR-
・ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装
・カラー図解 Raspberry Piではじめる機械学習 基礎からディープラーニングまで (ブルーバックス)
 画像認識プログラミングレシピ")
*1:切り出しの際にも前処理と言えるような処理もあり、やや境界は曖昧です