自分で用意した画像から手書き数字の切り出し→前処理と行なってきました。今度はこれらの手書き数字をMNISTデータセットで学習させた畳み込みニューラルネットワーク(convolutional neural network:CNN)に読ませるということをやってみます。また、モデルで分類する数字画像は一文字ずつバラバラの数字ですが、元の画像の位置に応じて数値としてCSVファイルに書き込みます。

- Keras&TensorFlowでディープラーニング
- CNNモデルの構築
- MNISTデータセットでCNNモデルを学習する
- 保存したモデルを手書き数字に利用する
- 予測した数字を数値としてファイルに書き込む
- 参考
Keras&TensorFlowでディープラーニング
KerasはPythonプログラミングにおいて、深層学習フレームワークであるTensorFlowをバックエンドとして利用することができるライブラリです*1。実際にモデルの学習などの処理を行うのはTensorFlowですが、Kerasを使うことでシンプルに実装することが可能となります。
Anaconda環境では以下のコマンドで入れることができます。
(CPU版):conda install tensorflow
(GPU版):conda install tensorflow-gpu*2
手元のPCにGPUがない場合はCPU版ということになりますが、ディープラーニングの学習にはCPUだと時間がかかるので、その場合はGoogleのウェブサービスColaboratoryを使うというのが断然お勧めです。Colaboratoryでは計算スピードの速いGPUを無料で使うことができ、Googleのユーザーアカウントさえあれば面倒な環境構築などもなく簡単に始めることができます。*3
colab.research.google.com
ということで、今回はモデルの学習はColaboratoryで行い、そのモデルを保存→ダウンロード→ローカルのPC上でロードして手書き数字認識をする、という流れでやりたいと思います。
CNNモデルの構築
数字画像の識別を行う学習モデルはCNNと呼ばれる空間的な特徴を捉えることができる層を持つ、画像の分類に適したニューラルネットワークです。
今回は数字認識を利用したアプリケーションを作るというのが目的なので、あまり詳細には立ち入らず取りあえずこのアプリケーションの完成を目指します。なお、CNNの構成は書籍『ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装』を参考にしました。*4
MNISTの精度だけでみれば、もっとシンプルなモデルでも99%を超える結果が得られますが、畳み込み層と全結合層を重ねて少し形を変えてみました。
概要を書くと、
・畳み込み層のフィルタは前から順に16、32、64と増えていく
・畳み込みフィルタは3×3
・活性化関数はReLU
・Dropoutレイヤを適宜使用
となります。
def cnn(input_shape, num_classes): model = Sequential() model.add(Conv2D(16, kernel_size=(3, 3), activation='relu', input_shape=input_shape)) model.add(Conv2D(32, (3, 3), activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Conv2D(64, (3, 3), activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.3)) model.add(Flatten()) model.add(Dense(128, activation='relu')) model.add(Dropout(0.3)) model.add(Dense(num_classes, activation='softmax')) model.summary() return model
MNISTデータセットでCNNモデルを学習する
MNISTデータセットをロードして後、学習モデルに渡すにはデータ配列の形状を変換し、データの調整をする必要があります。
def preprocess(data, label_data= False, num_classes=10): if label_data: # 教師ラベルをone-hotベクトルに変換する data = tf.keras.utils.to_categorical(data, num_classes) else: data = data.astype('float32') data /= 255 return data
# MNISTデータセットのロードと前処理 mnist = tf.keras.datasets.mnist (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train, x_test = x_train.reshape((60000, 28, 28, 1)), x_test.reshape((10000, 28, 28, 1)) x_train, x_test = [preprocess(d) for d in [x_train, x_test]] y_train, y_test = [preprocess(d, label_data=True) for d in [y_train, y_test]]
Kerasから取得したデータ型はuint8(0~255の分布)ですが、これをfloat32に変換後、255で割って0~1の間になるよう正規化します。また、教師ラベルのデータは画像に書かれた数字が与えられている(例えば、手書きで「5」と書かれた画像にはラベルも「5」となっている)ものを、keras.utils.to_categoricalメソッドでone-hotベクトル(数字dならば、d番目だけ1でそれ以外はすべて0)に変換しています。
続いてコンパイルと学習です。
# モデルのコンパイルと学習 model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy']) model.fit(x_train, y_train, batch_size=128, epochs=20, validation_split=0.2, callbacks=[TensorBoard(log_dir=log_dir), EarlyStopping(monitor='val_loss', patience=2, verbose=0, mode='auto')], verbose=1)
compileメソッドでは次の項目を設定します。
- 最適化アルゴリズム(optimizer)
- 損失関数(loss)
- 評価関数のリスト(metrics)
fit()に学習(訓練)データ、教師ラベルを与えて学習を行います。他にバッチサイズ(全データからランダムに取り出したデータの個数)、エポック(全てのデータが一巡して学習で利用される時間単位)、検証データの割合も設定します。
これらのパラメータは参考書籍やTensorFlowチュートリアル、Kerasドキュメントあたりを参考に設定しました。
なお、先ほどMNISTデータセットのラベルデータをone-hot表現に変換したと書きましたが、compileメソッドのlossを'sparse_categorical_crossentropy'で与えてやると、元のラベルデータのままでも良いようです(TensorFlowチュートリアルはこの方法です)。これだとコードが少しでも短くなりますね。
あと、コールバック(callbacks)にEarlyStopping()を指定することで、学習が進み過ぎることによる過学習(過剰適合)を避けることができます。過学習の根本的な対策としては、学習データの数を増やしたり、正則化といった方法がありますが、Early Stoppingは汎化性能が悪くなる前に学習を打ち切ります。
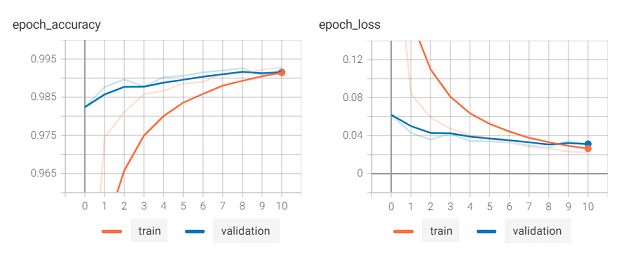
下図はこのモデルを60エポックまで学習したときの学習データと検証データのloss(損失)です。

学習を繰り返すと、学習データのlossは下がり続けていきますが、epochが10~15のあたりから検証データのlossは増加傾向となっています。
この検証データのlossが学習中に一旦下がった後に増加し始めることは過学習のサインであるため、その値をモニターすることでエポックで指定した数に達する前に自動的に学習をストップさせます。学習においては、モデルがデータを記憶することではなく未知(初見)のデータに対する汎化性能が大事なので、学習データの精度だけを見ていては駄目だということですね。
最後にテストデータでモデルを評価します。
score = model.evaluate(x_test, y_test, verbose=0) print("Test score: ", score[0]) print("Test accuracy: ", score[1])
最終的に出力は以下のようになりました。
Test score: 0.023204665631055832 Test accuracy: 0.9925000071525574
学習後にColaboratory上で以下のコマンドを続けて入力してTensorBoardを起動すると学習のプロセス(下図:精度と損失)を確認することができます。
load_ext tensorboard
tensorboard --logdir=./logdir
モデルの構造、モデルパラメータ(重み)を保存するには以下のコードを書いておきます。
model.save('./my_cnn.h5')
これらのコードはColaboratory上で実行しました。なお、実行の際には「ランタイム」→「ランタイムのタイプを変更」でハードウェアアクセラレータはGPUを選んでおきます。だいたい1分程度で終了しました。
import os import tensorflow as tf from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Conv2D, MaxPooling2D from tensorflow.keras.layers import Flatten, Dense, Dropout from tensorflow.keras.callbacks import TensorBoard, EarlyStopping def cnn(input_shape, num_classes): model = Sequential() model.add(Conv2D(16, kernel_size=(3, 3), activation='relu', input_shape=input_shape)) model.add(Conv2D(32, (3, 3), activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Conv2D(64, (3, 3), activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.3)) model.add(Flatten()) model.add(Dense(128, activation='relu')) model.add(Dropout(0.3)) model.add(Dense(num_classes, activation='softmax')) model.summary() return model def preprocess(data, label_data= False, num_classes=10): if label_data: # 教師ラベルをone-hotベクトルに変換する data = tf.keras.utils.to_categorical(data, num_classes) else: data = data.astype('float32') data /= 255 return data if __name__ == '__main__': IMAGE_SHAPE = (28, 28, 1) # MNIST画像フォーマット. 28x28ピクセルのグレースケール画像 NUM_CLASSES = 10 # 出力は0~9の10クラス log_dir = os.path.join(os.getcwd(), 'logdir') if os.path.exists(log_dir): import shutil shutil.rmtree(log_dir) os.mkdir(log_dir) # CNNモデルの構築 model = cnn(IMAGE_SHAPE, NUM_CLASSES) # MNISTデータセットのロードと前処理 mnist = tf.keras.datasets.mnist (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train, x_test = x_train.reshape((60000, 28, 28, 1)), x_test.reshape((10000, 28, 28, 1)) x_train, x_test = [preprocess(d) for d in [x_train, x_test]] y_train, y_test = [preprocess(d, label_data=True) for d in [y_train, y_test]] # モデルのコンパイルと学習 model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy']) model.fit(x_train, y_train, batch_size=128, epochs=20, validation_split=0.2, callbacks=[TensorBoard(log_dir=log_dir), EarlyStopping(monitor='val_loss', patience=2, verbose=0, mode='auto')], verbose=1) # テストデータを使って精度を検証 score = model.evaluate(x_test, y_test, verbose=0) print("Test score: ", score[0]) print("Test accuracy: ", score[1]) model.save('./my_cnn.h5')
保存したモデルを手書き数字に利用する
ここからはtensorflowをインストールしたローカルのPC上で行います。Colabolatory上で保存した"my_cnn.h5"をダウンロードして数字認識を行うpyファイルと同じディレクトリに置いた後、学習済みのモデルを読み込んで予測を行うには以下のようにpredict()を使います。
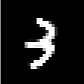
from tensorflow.keras.models import load_model def read_num_img(file): img = cv2.resize(cv2.imread(file, cv2.IMREAD_GRAYSCALE), (28, 28)).astype(np.float32) img /= 255 return img.reshape(1, 28, 28, 1) # 学習時と同じ形状(枚数, 横, 縦, チャンネル)に合わせる model = load_model('./my_cnn.h5') img = read_num_img(png_file) y = model.predict(img) print(np.round(y[0], 3)) # 小数点以下3桁で丸める # [0. 0. 0. 0.989 0. 0. 0. 0. 0. 0.011] pred = np.argmax(y) print(pred) # 3
yはモデルの最後にある出力層のソフトマックス関数の出力で、入力された値が正規化(出力の和が1になるよう変換)されています。手書き数字認識は10クラス分類なので、前から順に0, 1, …, 9である確率を示していることになります。
この出力yの中から最大の値(確率)に対応するクラスをモデルの予測とするので、np.argmax()で取得したインデックスが認識結果となります。
ちなみに、数字画像の読み込みは今まで使ってきたOpenCVで書きましたが、複雑な処理をするわけではないので画像処理ライブラリのPillowでもOKです。
予測した数字を数値としてファイルに書き込む
モデルを使った数字認識は一枚一枚の数字画像について行いますが、これは1~4桁の数値として手書きした一部です。なので最終的には認識結果の数字をつなげて数値としてCSVファイルに書き込みます。(実際のアプリケーションではExcelファイルの所定の位置に書き込みますが、ここでは簡潔さを優先してCSVファイルに書き込むコードとしました)
行数×列数のゼロの2次元配列tableをnp.zeros()で作成しておき、数字画像ファイルの名前から位置(行と列)の情報を取得して、対応するインデックスのところに認識結果(pred)を格納していきます。
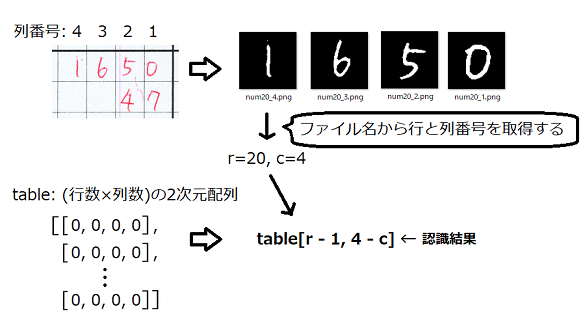
def insert_prediction(tbl, f_name, pred, max_c=4): row, col = f_name[3:].split('_') # 保存ファイル名は'num行_列' # 列番号→インデックス(1→3, 2→2, 3→1, 4→0)に変換 tbl[int(row) - 1, max_c - int(col)] = pred
数字画像の切り出し時は右端が1列目としてファイルに名前をつけましたが、numpy配列では左端がインデックス0なので、それに合わせて列番号を変換しています。
あとはCSVファイルへの書き込みです。以下のコードのように2次元配列の行ごとに要素を連結させ、csvモジュールのwriterows()メソッドで2次元配列を一気に書き込んでいます。
>>> table = np.array([[1, 2, 3, 4], [0, 0, 5, 6], [0, 7, 8, 9], [0, 0, 0, 1]]) >>> table array([[1, 2, 3, 4], [0, 0, 5, 6], [0, 7, 8, 9], [0, 0, 0, 1]]) >>> [[''.join(map(str, n))] for n in table] [['1234'], ['0056'], ['0789'], ['0001']]
with open(save_path + '/' + dir.name + '.csv', 'w', newline='') as f: writer = csv.writer(f) values = [[''.join(map(str, n))] for n in table] writer.writerows(values)
スペースの都合上すべてはお見せできませんが、CSVファイルへの書き込み後は以下のようになります。
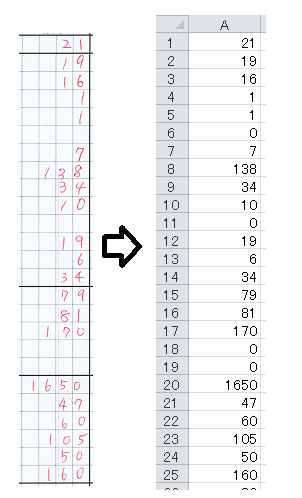
とりあえず今回で「数字認識を使って棚卸を自動化するアプリケーションを作る」でのアプリケーション部分のコードは終わりです。次回は集めた数字画像をプログラム中で手軽に使えるようデータセットを作成したいと思います。
www.yakupro.info
参考
・TensorFlow, Kerasの基本的な使い方(モデル構築・訓練・評価・予測) | note.nkmk.me

 画像認識プログラミングレシピ")
フォルダ構成とCSVファイルに認識結果を書き込むコードです。
└── work
├── my_cnn.py
├── my_cnn.h5
├──clipped_png
│ ├── A1(この中に切り取った1枚ずつの数字画像pngファイルがある)
│ │ ・
│ │ ・
│ └── ZX
└── 読み込み結果(my_cnn.pyコードを実行すると作成される)
├── A1.csv
│ ・
│ ・
└── ZX .csv
import csv, os, pathlib import numpy as np import cv2 from tensorflow.keras.models import load_model def read_num_img(file): img = cv2.resize(cv2.imread(file, cv2.IMREAD_GRAYSCALE), (28, 28)).astype(np.float32) img /= 255 return img.reshape(1, 28, 28, 1) def insert_prediction(tbl, f_name, pred, max_c=4): row, col = f_name[3:].split('_') # 保存ファイル名は'num行_列' # 列→インデックス(1→3, 2→2, 3→1, 4→0)に変換 tbl[int(row) - 1, max_c - int(col)] = pred if __name__ == '__main__': current_dir = os.path.dirname(os.path.abspath(__file__)) model = load_model('./my_cnn.h5') current_dir = os.path.dirname(os.path.abspath(__file__)) png_dir = '/clipped_png' scan_dir = pathlib.Path(current_dir + png_dir).glob('*') max_row = 42 max_col = 4 for dir in scan_dir: print(dir.name) table = np.zeros((max_row, max_col), dtype=np.uint8) for png_file in dir.glob('*'): # 数字画像の読み込みと数字認識 img = read_num_img(str(png_file)) y = model.predict(img) pred = np.argmax(y) # 認識結果を2次元配列に格納する insert_prediction(table, png_file.stem, pred) save_dir_list = [current_dir, '読み込み結果'] save_path = os.path.join(*save_dir_list) os.makedirs(save_path, exist_ok=True) # CSVファイルに書き込む with open(save_path + '/' + dir.name + '.csv', 'w', newline='') as f: writer = csv.writer(f) values = [[''.join(map(str, n))] for n in table] writer.writerows(values)