テキストの特徴抽出の手法として文書を単語の集合としてみるBag of Words(BoW)表現について前に書きましたが、今回は単語を数値ベクトルに変換する手法についてです。
- 単語の分散表現とは
- Word2Vec
- Wikipediaの特定カテゴリの記事にWord2Vecを使う
- gensimによるWord2Vecのパラメータを詳しくみる
- 類似度が高い単語のランキングを表示する
- 分散表現を用いてアナロジー(類推)問題を解いてみる
- Word2Vecで何ができるか?
- 参考
単語の分散表現とは
テキスト中の単語を固定長のベクトルで表現したもので、そのベクトルは単語自体の意味を反映しています。BoWのようなone-hot表現ではベクトル中の対応する要素のみを1、他のすべての要素を0で表現しましたが、分散表現ではベクトルのすべての次元が0でない実数値の密なベクトルとなります。
この分散表現を得るための手法の多くでは、分布仮説という次のような考えをベースにしているそうです。
似た文脈を持つ単語は似た意味を持つ
たとえば、「天気予報では明日〇が降ると言っていた。」という文があったとき、
〇に入る単語としては、雨、雪、あられ、ひょう、などが考えられますが、どれを入れても不自然ではありません。つまり、これらはどれも似た(降水現象という)意味を持つ単語であり、同じような文脈で現れているといえます。
また、分散表現では、ベクトル同士の類似性と単語の意味的な類似性が相関するような形で変換されます。
Word2Vec
単語の分散表現の有名なものにニューラルネットワークを用いたWord2Vecがあります。入力に大規模なテキストコーパスを与えて学習すると、学習を終えたネットワークから、単語の分散表現を得ることができます。
Word2Vecには以下の2つのモデルがあります。
- CBOW(continuous bag-of-words)
- Skip-gram
大まかには次のようなものです。
CBOWモデル
文脈語(単語の文脈として用いる前後の単語)から中心語を予測するモデルです。
| 予報 | で | は | 明日 | ? | が | 降る | そう | だ |
|---|
たとえば、「予報では明日雨が降るそうだ」という文において、文脈語「明日」と「が」という入力に対しては、中心語が「雨」である確率が最大になるようネットワークの学習を行います。
これは、t番目の単語に対して、中心語から前後1の文脈語を考えた場合に、という式、すなわち「
と
が与えられたときに
が起こる確率」をモデル化していることになります。
Skip-gramモデル
こちらはCBOWとは逆で、ある単語が与えられたとき、その文脈語を予測するように学習します。先ほどの文でいうと、中心語「雨」に対して「明日」と「が」を予測できるよう学習を行います。
| 予報 | で | は | ? | 雨 | ? | 降る | そう | だ |
|---|
確率の表記を使っていうと、こちらがモデル化している式は(「
が与えられたときに
と
が同時に起こる確率」)です。
どちらのモデルも入力層、中間層、出力層のみからなる浅いニューラルネットワークですが、入力層と中間層をつないでいるネットワークの重みそのものが各単語の分散表現となります。
なお、CBOWはSkip-gramよりも高速であるものの、Skip-gramの方が低頻度語の予測には優れているそうです。
Wikipediaの特定カテゴリの記事にWord2Vecを使う
では実際にWord2Vecで単語の分散表現を獲得してみます。
ここでは学習に使うテキストデータとしてWikipediaの「医薬品」カテゴリの記事を使用します。
こちらの記事で取得したものを使用しましたので、よろしければご参照ください。
www.yakupro.info
モデルの作成は一から実装するのではなく、gensimというライブラリを使用します。
次のコマンドでインストール。
pip install gensim
anacondaを使っている場合、パッケージ管理ツールはcondaですが、ざっとネットで見てみたところ、『インストールにとにかく時間がかかる』、『pipで入れたものより実行速度が大幅に遅い』等あまりいい話を見なかった*1ので、pipでインストールすることにしました。
なお、分かち書きにはMeCabを使用しています。今回は医薬品関係のテキストを処理するため、医療用語辞書として「ComeJisyoUtf8-2」を追加しました。このあたりのことはこちらに記事にしています。
import os import MeCab from gensim.models import word2vec # gensimのWord2Vecを試す. # Wikipediaの記事をモデルに食わせて学習後, 与えた単語と類似度が髙い単語を表示する. DATA_DIR = 'D:\\data\\医薬品' # Wikipediaから取得した医薬品カテゴリの記事ファイルのある場所 def get_all_files(directory): for root, dirs, files in os.walk(directory): for file in files: yield os.path.join(root, file) def read_file(path): with open(path, 'r', encoding='utf-8') as f: return f.read() def tokenizer(text): tagger = MeCab.Tagger("-O chasen") lines = tagger.parse(text).splitlines() words = [] for word in lines: chunks = word.split('\t') # 数詞のみ除く if len(chunks) > 3 and (not chunks[3].startswith('名詞-数')): words.append(chunks[0]) return words # wordと類似度が髙い単語の上位n個を表示する def print_most_similar(word, n=5): print(word) words = model.wv.most_similar(positive=[word], topn=n) for i, w in enumerate(words, 1): print(str(i) + " " + w[0] + " " + str(w[1])) if __name__ == '__main__': sentences = [] for f_path in get_all_files(DATA_DIR): text = read_file(f_path) sentences.append(tokenizer(text)) model = word2vec.Word2Vec(sentences, size=100, window=10, min_count=3, workers=5, sg=0, hs=0, negative=5, cbow_mean=1, sample=1e-3, iter=30) # 学習したモデルを保存する model.save('./word2vec.model') # モデルを読み込むときは上の部分はいらない. これだけで良い # model = word2vec.Word2Vec.load('./word2vec.model') # 類似度が高い単語を表示 print_most_similar("副作用") print_most_similar("不眠") print_most_similar("阻害") print_most_similar("コントロール") print_most_similar("治験") print_most_similar("薬効") print_most_similar("医薬品情報") print_most_similar("陰性")
また、今回はコードを簡単にするため、自然言語処理では本来は外すことのできない単語の正規化やストップワードの除去等の前処理は行いませんでした。分かち書きの際に数詞を除いただけです。
下にプログラムの実行結果を載せていますが、これらの条件で行うと完全に一致はしなくても、だいたい似たような結果になると思います。なお、ネットワークの重みの初期値が毎回異なるため、毎回同じ結果とは限りません。*2
gensimによるWord2Vecのパラメータを詳しくみる
設定できるものすべてではありませんが、使用したものについて書きます。コード中ではデフォルト値のままでも書いているものもあります。
パラメータについての公式の説明はこちらです。
sentences
テキストを分かち書きした単語のリストのリストを渡すことができます。
次のようなリストです(公式サイトより)。
sentences = [["cat", "say", "meow"], ["dog", "say", "woof"]]
size
単語ベクトルの次元数。デフォルトは100。大きい程多くの学習データを必要とするが、より良い(精度の高い)モデルにつながる可能性がある。数十~数百程度が妥当だとのこと。
window
対象の単語から前後どれだけの単語を使って学習を行うか。「Maximum distance(最大距離)」という表現です。常にこの距離ではない、ということでしょう。デフォルトは5。
min_count
この数字未満の出現数のまれな単語は無視する。デフォルトは5。
workers
学習時に使用するスレッド数。マルチコアのマシンだと速くなる。デフォルトは3。
sg
skip-gramを使用するかどうか。0だとcbowモデル、 1だとskip-gramモデルを使用する。コーパスが大規模になるにつれて、低頻度の単語や類推問題の性能の点においてskip-gramモデルの方が優れているとのことですが、今回はコーパスが小さいためか、skip-gramではあまり良い結果は得られませんでした。*3そのためcbowモデルを使用しましたが、結果ははっきりとわかるくらい違いがあり、私の感覚に近い表現が得られました。
hs
デフォルトは0で、この場合はネガティブサンプリングが使用されるが、hs=1で階層的ソフトマックスを使用する。階層的ソフトマックスも高速化のための手法で、計算コストを抑えるために使用されます。
negative
モデルは正例(正しい答え)か負例(誤った答え)かで学習しますが、コーパスが大きくなると負例の数も膨大になる(=計算コストが高くつく)ため、負例は少数を確率的にサンプリングします。これをネガティブサンプリングといい、そのサンプリングに用いる単語数を設定できます。通常は5-20の間とのことですが、大きくすると当然学習にかかる時間は長くなります。コーパスが大きい場合は少なくても良いそう。
cbow_mean
cbowモデルの場合のみ適用される。0の場合は文脈語ベクトルの和、1の場合は平均を使用する。
sample
頻度の高い単語を切り捨てるための値を設定する。たとえば、英語だと「the」などは多くの単語の文脈で出現し、学習に必要な数以上にこの単語を含むサンプルが多くなり過ぎます。これに対処するため単語の頻度によってランダムに削除(ダウンサンプリング)します。範囲は(0, 1e-5)で、デフォルトは1e-3。でも、これだとデフォルトは範囲外ですが…。gensimではこの値をパラメータとする計算式を使用しており、この値が小さい程、単語が保持される確率が低くなるようになっているようです。
iter
コーパスを何回繰り返すか。反復回数。デフォルトは5。
類似度が高い単語のランキングを表示する
プログラムを実行すると、与えた単語に対して類似度が高い単語が5つずつ表示されます。右の数字は類似度を表しています。
私からみて、わりと納得がいくような結果が得られた単語を選んでみました。良いと思った試行回の結果です。中には「ん?」というものもありますが、だいたいどれも”似た文脈”で出てきそうな単語が並んでいるのではと思います。
しかし、「陽性」のところでは「陰性」が1番目に上がってきています。Word2Vecは対義語や多義語に弱いのだそうです。たしかに、「陽性」でも「陰性」でも「検査の結果は〇〇だった」のような文だと同じ文脈です。この傾向は単語を変えて試してみると、すぐに感じられると思います。対義語が重要な意味を持つアプリケーション等に利用する場合には、何らかの対処が必要になることでしょう。
また、多義語というのは、文字通り複数の意味を持つ語のことです。ここにはありませんが出てきそうなもので思いつくのは「DM」(糖尿病/ダイレクトメッセージ)などでしょうか。
副作用 1 低血糖 0.5658822059631348 2 有害事象 0.5652320981025696 3 眠気 0.5222797393798828 4 皮膚障害 0.5178262591362 5 悪心嘔吐 0.5110833644866943 不眠 1 動悸 0.8281195759773254 2 易刺激性 0.8275653123855591 3 耳鳴り 0.8216724395751953 4 不安 0.819955050945282 5 睡眠障害 0.8159047365188599 阻害 1 抑制 0.730728805065155 2 阻止 0.6628458499908447 3 遮断 0.6544621586799622 4 阻害剤 0.6416957378387451 5 妨げる 0.6296447515487671 コントロール 1 維持 0.6200644969940186 2 制御 0.597223162651062 3 モニタリング 0.5622754096984863 4 予測 0.559542179107666 5 測定 0.5552082657814026 治験 1 臨床試験 0.7469147443771362 2 海外 0.6117804050445557 3 臨床研究 0.5857583284378052 4 試験 0.5837343335151672 5 フェーズ 0.5697225332260132 薬効 1 薬理作用 0.6012215614318848 2 効果 0.5677321553230286 3 生薬 0.5124845504760742 4 利尿作用 0.49798858165740967 5 作用機序 0.47855547070503235 医薬品情報 1 source 0.7395623922348022 2 要旨 0.5549689531326294 3 言語 0.5537670254707336 4 資料 0.5525869131088257 5 集 0.5336570143699646 陽性 1 陰性 0.6898894906044006 2 再検査 0.6689844727516174 3 Ph 0.626990795135498 4 転移性 0.6059024930000305 5 ALL 0.595970630645752
分散表現を用いてアナロジー(類推)問題を解いてみる
Word2Vecで得られた分散表現ではさらに面白いことができます。
「king - man + woman = queen」や「東京 - 日本 + イギリス = ロンドン」などのように、類推問題を各単語ベクトルの加減算で解くことができます。
後者の例を式変形すると、「東京 - 日本 = ロンドン - イギリス」となり、これは両辺とも2つの単語の差が表すものがイコールである、という意味です。さらに言い換えると、「日本にとっての東京は、イギリスにとっての何?」という問いになります。この問いにおける、単語ベクトルの空間上での各単語の関係性は以下のようなイメージです。
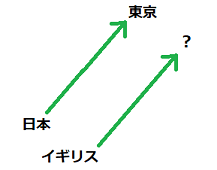
この類推問題を試してみるのに、今度は別のコーパスでやってみました。データについての詳細は差し控えますが、今度は以下のような前処理を施しました。
- MeCabではComeJisyoUtf8-2.dicと700近くの単語を登録したユーザ辞書を使用
- 400語程度表記ゆれの統一を行った。(LVFXとレボフロキサシンは同じものとして扱うなど)
- ストップワードを設定(100未満)
この前処理部分以外のコード、Word2Vecのモデルやパラメータも上のプログラムとほぼ同じです。
次のようなコードで演算を行います。
def analogy(A, X, B): # X - A + B = ? # AにとってのXは, Bにとっては何? print('\n[analogy] ' + X + ' - ' + A + ' + ' + B + ' = ?') for i, w in enumerate(model.wv.most_similar(positive=[B, X], negative=[A], topn=3), 1): print(str(i) + " " + w[0] + " " + str(w[1])) analogy("インスリン", "低血糖", "DOAC") analogy("薬剤師", "情報提供", "医師") analogy("抗菌薬", "TDM", "ワーファリン")
以下、実行結果です。
[analogy] 低血糖 - インスリン + DOAC = ? 1 出血リスク 0.4432564377784729 2 出血 0.40226882696151733 3 イグザレルト 0.388386070728302 [analogy] 情報提供 - 薬剤師 + 医師 = ? 1 紹介状 0.5322709083557129 2 専門 0.4973721504211426 3 Dr 0.48535287380218506 [analogy] TDM - 抗菌薬 + ワーファリン = ? 1 INR 0.4912528097629547 2 治療域 0.41000866889953613 3 評価 0.4095485508441925
- 1つ目の問いは「インスリンにとっての低血糖はDOAC*4にとっては何か?」です。ここは代表的な副作用である出血を意味するワードが1番目と2番目に上がっています。
- 2つ目は「薬剤師にとっての情報提供は医師にとっては何か?」です。ここは私は「診察」のような単語をイメージしましたが、1番目は「紹介状」となりました。ちなみに、紹介状とは、医師が他の医療機関(医師)に患者さんを紹介するときに作成される書類のことです。推測ですが、文脈上で「情報提供」という言葉が使われる対象として「医師」や「医療機関」のような言葉が多かったのかもしれません。
- 3つ目です。INR(PT-INR)は血液の凝固能を示し、ワーファリンの投与量管理に用いられます。この答えには、抗菌薬にとっての*5TDMという言葉の「適正な投与設計を行うためのものである」という意味がうまく埋め込まれていると思います。
単語を数値で表現するだけでなく、このような連想ゲームのようなことができ、しかも人間の直感と合致するような単語間の関係性も捉えられている点が興味深いです。
Word2Vecで何ができるか?
Q&Aやチャットボット、機械翻訳、感情分析(テキストデータの感情判定)などに応用されているそうです。Q&Aは、複数語のキーワード検索で探すよりも、より本質に近い意図を汲み取ったかのような質問を探すことができるのでしょうか。データの蓄積が大量にないと、なかなか恩恵を受けられそうにない気もします。他の例については、アンケートに対してポジティブ・ネガティブを判定したり、どのような質問や意見が多いか、などをまとめることで分析に活かせる場面がありそうです。
参考
・ゼロから作るDeep Learning2 自然言語処理編
・15Stepで踏破 自然言語処理アプリケーション開発入門
・Word2Vecを理解する - Qiita
・Word2Vec:発明した本人も驚く単語ベクトルの驚異的な力 - DeepAge
・直感 Deep Learning ―Python×Kerasでアイデアを形にするレシピ
